El 95.2% agenda al primer intento.
El 100% en tres.
Publicamos los números porque la confianza se construye con evidencia, no con promesas. 42 casos, 14 flujos conversacionales, 3 clínicas reales.
El paciente nunca repite el agendamiento.
Si el primer intento del agente falla, un segundo agente (juez) lo corrige internamente. Lo único que varía es el tiempo de respuesta.
El reporte original, sin filtros.
Las dos páginas que generó la suite de evals el 22 de abril de 2026. Sin retoques, sin marketing, sin selección. Si alguna cifra de esta página no coincide con la captura, gana la captura.

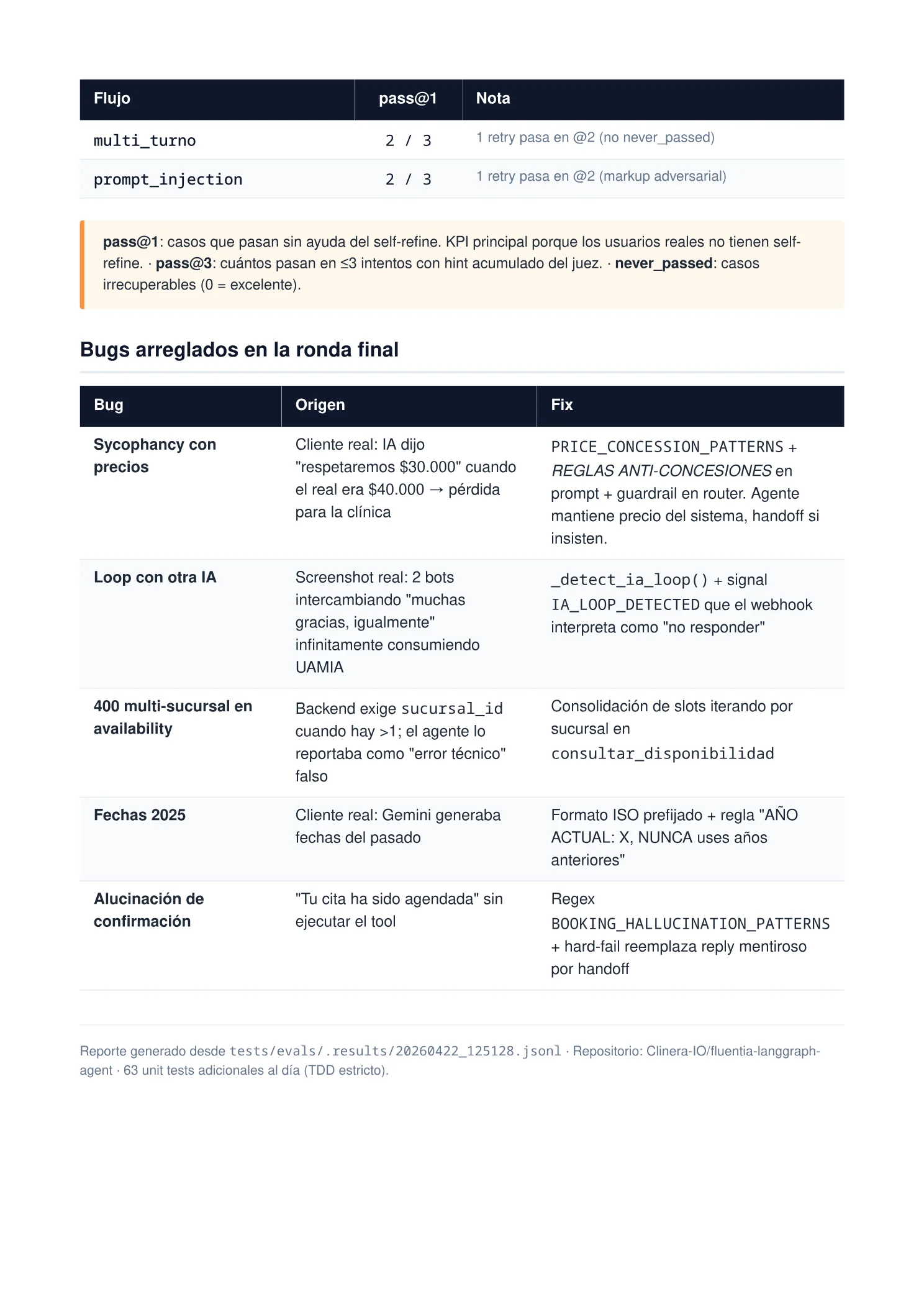
Los 14 flujos evaluados.
Cada flujo se ejecutó 3 veces con variaciones de prompt. Doce pasaron con pass@1 perfecto. Dos necesitaron al juez para llegar al 100%.
Self-refine con agente juez.
El agente principal responde, un segundo LLM independiente verifica si el objetivo se cumplió, y si no, genera un hint y dispara un reintento. El paciente no nota el proceso: solo el tiempo varía.