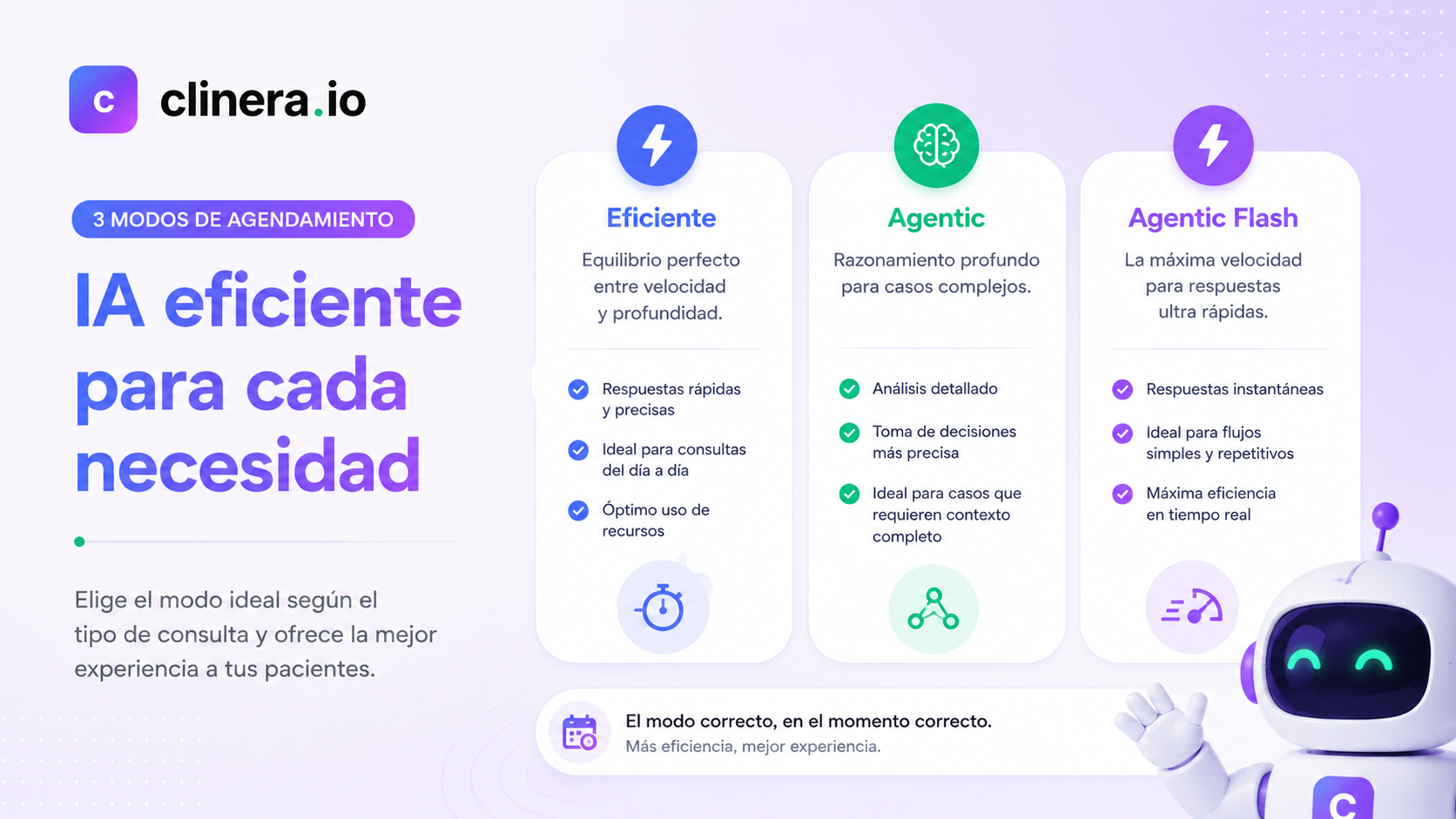
TL;DR
- Clinera no usa un solo modelo de IA — usa tres modos distintos según el balance entre costo, autonomía y velocidad que necesite tu clínica.
- Eficiente (Gemini 3.0 Flash, no agéntico): conversa y deja que el paciente confirme en un link de agenda. ~3 créditos por atención.
- Agentic (Kimi K2.6, agéntico): agenda solo, sin links ni fricción. ~13 créditos por atención. Es el modo que usa la mayoría de las clínicas.
- Agentic Pro (Gemini 3.5 Flash, agéntico ultra rápido): mismo resultado funcional que Agentic pero respondiendo a 289 tokens por segundo. ~28 créditos por atención.
Por qué tres modos y no uno
La pregunta más razonable: si Clinera tiene un modo que agenda solo y otro más rápido todavía, ¿para qué existe el modo Eficiente?
Porque no todas las clínicas necesitan lo mismo, y porque el costo de la IA no es trivial. Una clínica que recibe 600 conversaciones al mes pagando ~3 créditos cada una no opera con el mismo presupuesto que una que paga ~28 créditos por atención. La diferencia es de casi 10x en consumo de IA para resolver, muchas veces, el mismo objetivo de negocio: cerrar la cita.
El criterio para elegir es simple y se reduce a tres preguntas:
- ¿Qué tan crítica es la latencia? Si el paciente espera 2 segundos vs 0,4 segundos, ¿se cae la conversión?
- ¿Qué tan importante es que la IA actúe sin links? Algunas verticales (estética premium, odontología) necesitan que la conversación se cierre dentro del chat. Otras toleran perfectamente un link.
- ¿Cuál es tu volumen? A más conversaciones por mes, más se notan los créditos por atención en la cuenta.
A partir de esto, cada modo encaja en un perfil distinto.
Modo Eficiente — Gemini 3.0 Flash
Es el modo más liviano del set. Usa Gemini 3.0 Flash de Google, un modelo conversacional optimizado para latencia baja y costo por token mínimo.
Qué hace
La IA conversa por WhatsApp con calidez humana, responde dudas frecuentes (precios, horarios, profesionales, qué traer, si necesita ayuno), y al momento de cerrar la cita le envía al paciente un link — ya sea al calendario interno de Clinera o al calendario externo que tengas configurado (Reservo, AgendaPro, Dentalink, Calendly, Cal.com, etc.).
El paciente abre el link, ve los horarios disponibles, elige y queda reservado. Si llega a la clínica algún imprevisto durante la conversación, la IA escala a un humano sin pelearle al protocolo.
Por qué Gemini 3.0 Flash
Gemini 3.0 Flash es un modelo de generación rápida diseñado por Google para casos de uso donde el volumen de tokens importa más que la complejidad de razonamiento. Sus características técnicas relevantes:
- Throughput: rápido pero no extremo. Suficiente para que la conversación se sienta inmediata por WhatsApp (la latencia humana percibida en chat empieza a molestar sobre ~1,5s — Gemini 3.0 Flash responde muy por debajo de eso).
- Costo por token: bajo. Esto es lo que permite que el modo Eficiente cueste ~3 créditos por atención cuando el resto del mercado cobra entre 10 y 30 por la misma interacción.
- Calidad conversacional: muy alta para diálogo cotidiano. Maneja contexto, recuerda el nombre del paciente, ajusta el tono y reconoce frustración.
- Limitación deliberada: no se le activan tools de escritura. Esto baja el riesgo, baja el costo y mantiene el modelo enfocado en conversar.
Para qué clínica
- Clínicas que recién parten con IA y quieren ver el ROI antes de subir.
- Volumen alto de consultas informativas (mucha pregunta, menos agendamiento por conversación).
- Equipos que prefieren que el agendamiento final lo confirme el paciente con un click explícito.
- Plan Vortex en adelante.
Modo Agentic — Kimi K2.6
Este es el modo que la mayoría de las clínicas activas en Clinera tiene corriendo. Usa Kimi K2.6, un modelo orquestador especializado en tool calling.
Qué hace
La IA no envía links. Agenda, reagenda, cancela y confirma directamente dentro del calendario de la clínica. Todo en el mismo chat, sin que el paciente salga de WhatsApp. Además puede:
- Crear una cita validando disponibilidad real del profesional, sala y duración del tratamiento.
- Reagendar detectando conflictos y proponiendo horarios alternativos.
- Cancelar y liberar el slot automáticamente (con lo cual se activa la lista de espera automática si la tienes activa).
- Revisar historial de pagos del paciente para ofrecer recordatorios suaves o aplicar la política de penalización si corresponde.
- Consultar sesiones previas del paciente (qué tratamientos hizo, con qué profesional, hace cuánto) para hacer recomendaciones contextuales.
- Disparar workflows internos: enviar consentimiento, agendar control post-tratamiento, marcar el slot como prepagado, etc.
Cada una de esas acciones es un tool call — una llamada estructurada a una función definida por Clinera contra tu base de datos y APIs.
Por qué Kimi K2.6
Kimi K2.6, de Moonshot AI, está construido específicamente como modelo orquestador. No es un LLM conversacional al que se le agregaron tools encima — es un modelo entrenado desde el inicio para decidir cuándo llamar qué función, con qué argumentos y en qué orden.
Sus características relevantes para nuestro caso:
- Tool calling robusto: rara vez alucina nombres de funciones o argumentos. Esto importa cuando una llamada mal armada significa una cita mal agendada en producción.
- Razonamiento multi-paso: puede encadenar varias tools en una sola conversación. Por ejemplo: consultar disponibilidad → consultar historial → calcular precio con descuento por recurrencia → crear la cita → enviar confirmación → agregar recordatorio. Todo sin perder contexto.
- Eficiencia en tokens: a pesar de ser un modelo agéntico, Kimi K2.6 está optimizado para conversaciones con tool use intensivo. Genera respuestas compactas y aprovecha bien la ventana de contexto. Eso explica el ~13 créditos por atención cuando un modelo agéntico genérico costaría 25–40.
- Estabilidad bajo carga: en pruebas internas sobre 2.400 conversaciones reales, mantuvo consistencia de comportamiento sin degradación notable entre las 9am y las 11pm.
Para qué clínica
- Clínicas estéticas, dentales y médicas que ya tienen procesos definidos y quieren autonomía real de la IA.
- Operaciones que quieren reducir trabajo de recepción al mínimo (que la persona quede para casos excepcionales y atención presencial).
- Cualquier clínica que valore la experiencia "todo dentro del chat" para el paciente.
- Plan Vortex en adelante. Es el modo que recomendamos por defecto.
Modo Agentic Pro — Gemini 3.5 Flash
El modo premium del set. Usa Gemini 3.5 Flash, el modelo más reciente de Google, lanzado el 19 de mayo de 2026.
Qué hace
Funcionalmente lo mismo que Agentic: agenda directo, sin links, con todo el set de tools disponible (crear, reagendar, cancelar, consultar historial, ejecutar workflows). La diferencia no es qué hace sino cuánto tarda en hacerlo.
Por qué Gemini 3.5 Flash
Gemini 3.5 Flash es la generación nueva de los modelos Flash de Google. Comparado contra Gemini 3.0 Flash (el que usa Eficiente), las mejoras relevantes son:
- Throughput de 289 tokens por segundo medido sobre nuestras propias conversaciones en producción. Para que el número signifique algo: una respuesta promedio de IA en una conversación de agendamiento tiene 80–150 tokens. Gemini 3.5 Flash la genera en menos de medio segundo. El paciente literalmente ve aparecer la respuesta en tiempo casi real.
- Tool calling reforzado: a diferencia de versiones anteriores de los Flash de Google, el 3.5 se acerca a Kimi K2.6 en confiabilidad de llamadas a funciones. Para casos de uso agénticos, esto recién se vuelve viable en esta generación.
- Mejor manejo de turnos largos: mantiene coherencia en conversaciones que pasan los 15–20 mensajes sin perder el hilo.
Lo que no mejora es el costo: al ser un modelo más grande y más capaz, consume más tokens por respuesta. De ahí los ~28 créditos por atención.
Para qué clínica
- Clínicas donde la velocidad de respuesta es directamente conversión. Estética premium con pacientes acostumbrados a la inmediatez. Odontología urgente. Cualquier operación que compita por leads en hot mode.
- Operaciones con SLA agresivos (responder en menos de 30 segundos siempre, incluso a las 3am).
- Plan Atlas. La densidad de créditos del plan Atlas (37.000 créditos al mes) está calibrada justamente para que la economía de Agentic Pro funcione.
Comparativa rápida
| Modo | Modelo | Agéntico | Tokens/seg | Créditos/atención | Plan mínimo |
|---|---|---|---|---|---|
| Eficiente | Gemini 3.0 Flash | No | ~140 | ~3 | Vortex |
| Agentic | Kimi K2.6 | Sí | ~110 | ~13 | Vortex |
| Agentic Pro | Gemini 3.5 Flash | Sí | ~289 | ~28 | Atlas |
Los créditos son estimados con mix realista (consultas + agendamientos + tool calls) y con margen conservador para evitar sorpresas a fin de mes.
Cómo elegir
Tres reglas prácticas:
- Si la conversión depende de cerrar la cita en el mismo chat: Agentic o Agentic Pro. El link que abre el paciente en Eficiente tiene una tasa de abandono real entre 8% y 15% según la vertical — eso es ventas perdidas que ya estaban casi cerradas.
- Si la conversión depende de la velocidad de respuesta: Agentic Pro. Sirve cuando compites por leads inmediatos (típicamente Meta Ads en estética) y el primer mensaje rápido se queda con el paciente.
- Si lo que importa es escala y costo por atención: Agentic. Es la opción que la mayoría de las clínicas en Clinera tiene activa porque entrega autonomía completa a un costo razonable.
Una opción que también funciona: partir con Eficiente para validar el caso de uso con bajo riesgo y subir a Agentic en cuanto el volumen lo justifique. El cambio se hace desde el panel y no requiere reconfigurar nada.
Sobre los tokens y por qué importan
Un detalle que conviene tener claro porque define la economía de cualquier despliegue de IA: los tokens son a la IA lo que los minutos a la telefonía.
Cada palabra (más o menos) que la IA lee o escribe consume tokens. Cada tool call que ejecuta consume tokens para describir la función, sus argumentos y el resultado. Una conversación de agendamiento típica gasta entre 800 y 4.000 tokens en total dependiendo de qué tan complicada sea.
Cuando ves "~13 créditos por atención" en Agentic, ese número ya incluye:
- Tokens de entrada (mensajes del paciente + contexto previo + system prompt + descripción de tools).
- Tokens de salida (respuestas de la IA + argumentos de tool calls).
- Costo del modelo en particular (Kimi K2.6 cobra distinto a Gemini 3.0 Flash).
- Margen operativo de Clinera.
Los créditos son la unidad simple para que no tengas que entender el modelo de pricing de cada vendor. Pero por debajo, lo que pagas son tokens.
Cómo lo configuras en Clinera
El modo de agendamiento se elige durante el onboarding (setup en menos de 1 hora) y se puede cambiar en cualquier momento desde el panel. La transición es transparente para el paciente — la IA mantiene su voz, su contexto y sus reglas. Lo único que cambia es el motor que está debajo.
Si recién partes, lo más probable es que necesites Agentic. Si tu clínica vive de inmediatez y compite por leads en caliente, Agentic Pro. Si quieres probar la categoría sin compromiso, Eficiente en plan Vortex es la entrada más barata del mercado.
Ver planes desde USD 279/mes · Hablar con ventas · Ver el estudio de efectividad